引言
中日韓字符資料在電腦中的情況
香港中文大學圖書館機讀目錄歷史
INNOPAC的「Big5對應表」與「UTF8對應表」的矛盾
香港圖書館的Unicode工作計劃
香港中文大學修改圖書館機讀目錄資料庫過程
新UTF-8對應表diac.utf8.hkiug下資料用戶軟件的設定
HKIUG的跟進工作
未來
結語
1. 引言
圖書館目錄的功能是要幫助讀者有效地查詢,辨識,選取圖書館内的資源。自從電腦作業系統支援中文字以來,中文字碼的選用是華文圖書館編目工作的一大挑戰。 圖書目錄在圖書館系統的中文輸入和内碼限制下,不單要正確顯示書目紀錄,亦要兼顧用戶端的電腦界面以支援有效檢索。書目紀錄的字碼不同,也成了合作編目的障礙。編目者一般會採用大五碼(Big5)、國標(GB)、CCCII、EACC或Unicode(單一碼)等輸入資料,而INNOPAC系統則以CCCII/EACC為内碼。以往香港圖書館大多使用Windows95或Windows98外掛Big5輸入系統, 亦有使用DOS版含繁簡体字的CCCII大漢字形檔。但由於INNOPAC 的Webopac使用Big5 port,只有繁體字介面,讀者也只能以繁體字查詢。
踏入2000年,Unicode平臺的個人電腦作業系統日漸普及,如Windows2000, WindowsXP等。用戶多以Unicode介面輸入資料或查詢。此舉形成了編目,内存及查詢的三個層面,各自使用不同的內碼介面。本文簡介中文字碼的問題;香港中文大學圖書館系統在2003年的書目紀錄字碼轉換工作;以及香港INNOPAC用戶組 (HKIUG) 單一碼計劃工作小組提出的建議和解決方法
2、中日韓字符資料在電腦中的情況
2.1 每一個中日韓字符對電腦來説,只是以一串内碼的形式存在電腦的記憶體中。流行的中文字編碼字元集有如下幾種:
字元集名稱 (character sets) |
流行範圍 |
| GB |
大陸 |
| Big5 |
香港、臺灣等地 |
| CCCII (Chinese Character Code for Information interchange中文資訊交換碼) |
圖書館系統,如:INNOPAC |
| EACC (East Asian Character Code 東亞字碼,可視為CCCII的子集) |
美國國會圖書館字碼標準(LC MARC 21 standard)http://www.loc.gov/marc/specifications/specchareacc.html |
| Unicode (單一碼) |
電腦作業系統廣泛採用,如wWindows 2000、Windows XP |
|
2.2 值得注意的是各種中文字編碼字元集均有個別的繁簡體字支援範圍。
|
字符數 |
碼點(code point) |
版本發佈 |
支援繁簡 |
連結特質 |
| Big5 |
13,053 |
14,758 |
1984 |
繁體 |
無 |
| GB18030 |
27,000 |
1.6萬 |
2000 |
繁/簡體 |
無 |
| CCCII |
75,684 |
830,584 |
1980 |
繁/簡體 |
有 |
| EACC |
15,728 |
830,584 |
1983 |
繁/簡體 |
有 |
| Unicode |
82,270 |
1.1百萬 |
2000(v.3) |
繁/簡體 |
無 |
|
2.3 各種中文字編碼字元集亦有個別的「碼點」,毫無關係。以 [余] 字為例:
字元集 |
[余] 的碼點 |
經過對應表在INNOPAC內存轉為CCCII碼 |
連結特性 |
| Big5 |
A745 |
Big5對應表:213131 |
CCCII與EACC同出一源,其中「尾4碼相同」,在索引時互相連結。
例如:
[余] 276076尾4碼連結
[餘] 216076
要注意的是 [余] 字常在姓氏中使用,依Big5對應表轉換後則為213131,無法連接 [餘] 216076 |
| GB 18030 |
5164 |
--- |
| CCCII |
276076 [余]
273131 [余]
(附: [餘] 216076) |
--- |
| EACC |
276076 [余]
(附: [餘] 216076) |
--- |
| Unicode |
4F59 |
UTF8對應表:276076 |
|
2.4 從上表可知,同一個 [余] 字,使用與繁體字「餘」相連的EACC 276076而不取其獨立的CCCII 213131,有索引上的優點。同樣,例如「餘數」這個詞組,繁體的「餘數」與簡體的「余数」能够互相連結索引。
|
3. 香港中文大學圖書館機讀目錄歷史
3.1 香港中文大學圖書館機讀目錄與其他香港的圖書館大致一樣,是使用繁體字編目,以Big5為内碼儲存。大學圖書館系統使用INNOPAC後,由於INNOPAC是以CCCII為中文字内存的系統,早期以Big5為内碼儲存的目錄於1995年一併轉換爲CCCII,以符合當時USMARC的標準(唯字碼不局限於EACC字元集)。對讀者提供的Webopac是Big5 port,只能顯示繁體字。
3.2 香港中文大學大學圖書館系統認爲簡體字書籍,應以簡體字著錄、儲存及在目錄上顯示。雖說簡體字書籍也可循用繁體字編目,但例如「杰」字出現在作者的名字某部分時,以「傑」字代替未必適當,甚至錯誤。因此爲了如實著錄,簡體字書籍還是以簡體字著錄為尚。自1996年開始,大學圖書館系統的機讀目錄已是繁簡並用了。
3.3 可是繁簡體字在Big5對應表轉換為CCCII後,尾4碼不連結,影響索引。且看「餘數」的「餘」,内碼經Big5對應表轉換為EACC 216076,與簡體的「余数」的「余」内碼則被轉換為CCCII 213131即為一例。大學圖書館系統爲了利用繁簡體字連結索引的特質,「余数」的「余」,使用了永麒公司的「大漢字庫」,選取以與「餘」相連的「余」(内碼EACC 276076)輸入。誠然對讀者來說,難免有點麻煩,要找出簡體字資料的「余数」的「余」(内碼EACC 276076),要輸入繁體字資料的「餘」(内碼EACC 216076),否則光是輸入「余」只會找出含姓氏「余」(内碼CCCII 213131)的書目資料。線上目錄檢索受到很大的限制,這種情況一直無法改善。
3.4 直至INNOPAC於2000年後提供了UTF8 port Webopac 繁簡並用的目錄,上述檢索限制的情況才有新發展。繁簡体字是可以一併查找及顯示。見附圖:
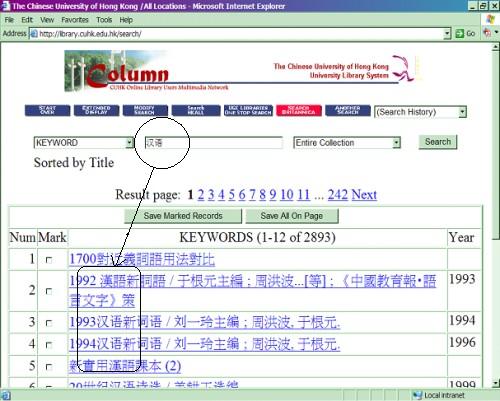
|
4. INNOPAC的「Big5對應表」與「UTF8對應表」的矛盾
可是,同樣是一個字符「余」,在INNOPAC系統中的「Big5對應表」與「UTF8對應表」選取對應CCCII的邏輯次序並不一致。用戶經Big5 port或UTF8 port會找到不一致的書目數量。換言之,在UTF8平台下輸入的字符儲存碼與Big5平臺輸入字符的儲存碼並不完全一樣,做成書目檢索上的混亂。請看下表查詢「余」字的情況:
Big5對應表架構 [余] 字內碼與Big5對應 |
查詢結果 |
| 內碼 |
Big5 |
<--選取表中較前條目 |
Big5 port輸入 [余] (A745)只會找出含姓氏「余」(213131)的書目 |
...
213131
276076
... |
A745
A745
|
UTF8對應表架構 [余] 字內碼與FTF8對應 |
查詢結果 |
| 內碼 |
Big5 |
<--選取表中較後條目 |
UTF8 port輸入 [余] (U+4F59)。由於與「餘」217076連結索引,所以只會把含繁體的「餘」字書目找出來。但此「余」(276076)又無法查找姓氏「余」(213131)的書目記錄。 |
...
213131
276076
... |
4F59
4F59
|
|
5. 香港圖書館的Unicode工作計劃
5.1 基於在Unicode環境下使用INNOPAC編目及讀者查詢目錄時會遇到的種種困難,香港中文大學大學圖書館系統邀請了香港各INNOPAC圖書館於2003年7月11日舉行了一次名為“Seminar on Using Unicode UTF-8 for Online Catalogue on INNOPAC System” 的討論會。各圖書館的代表在會上交流意見,並商討各種解決方案。同年7月, Hong Kong Innovative Users Group(香港Innovative用戶協會,簡稱HKIUG) 成立了HKIUG Working Group on Unicode Project (單一碼計劃工作小組)負責儘快訂出解決方案。
5.2 單一碼計劃工作小組的成員包括香港科技大學的林紀達先生,香港城市大學的黃秉傑先生,香港大學的陳偉明先生,香港中文大學的何以業。
5.3 單一碼計劃工作小組的目標有如下五個:
- 解決「Big5對應表」和「UTF-8對應表」選取内存CCCII不一致的難題
- 決定對應表中的那些應是「一EACC對一Unicode」或是複數對應,即「多EACC對一Unicode」
- 決定對應表應否只包含「EACC」或是「EACC+ CCCII」並存
- 清除對應表錯誤與缺漏
- 為將來「以Unicode為内存的資料庫」(Unicode based database)做好準備
5.4 經過三個月的反復討論,單一碼計劃工作小組於同年11月提出如下方案:
- 不再修訂Big5 對應表。原因是Big5對應表字量少;只支援繁體字;複數對應太多
- 重制新的 Unicode 對應表
- EACC<>Unicode 對應方面,以美國國會圖書館MARC 21為標準
- EACC 與 CCCII 重疊時,刪除CCCII (可參看下文5.5.b)
- 各館自行決定將屬於上項955對中以CCCII為內碼的資料轉換為對應的 EACC
- 對應表需包括「純粹CCCII」,即不是與EACC重覆的CCCII,以照顧非常用字(可參看下文5.5.c)
- 新對應表除了「一EACC對一Unicode」外,亦會包含「多EACC對一Unicode」;尾4碼相同者,容許複數對應;尾4碼不同者,需決定優先選取者(可參看下文5.5.d)
5.5 新的 EACC/CCCII<>UTF-8 對應表的建構的詳細工序見於黃秉傑先生在2003年12月第4屆 Hong Kong Innovative Users Group Meeting報告內的Procedures 部分。該部分的要點為:
- 以美國國會圖書館MARC21的東亞語文内碼表(http://www.loc.gov/marc/specifications/specchareacc.html) 為基準,抽取了15,673條EACC<>Unicode對應目,從INNOPAC舊對應表diac.utf8,刪除與LC重覆的部分。
- 從INNOPAC的舊diac.utf8對應表,刪除與EACC重覆的CCCII。此類内碼共 955對,例如:
可被刪除的CCCII |
Unicode |
字符 |
應使用的EACC |
| 213131 |
U+4F59 |
余 |
276076 |
| 21653E |
U+4F53 |
体 |
27615A |
| 213A79 |
U+5BB6 |
家 |
27323E |
- 加入INNOPAC舊對應表diac.utf8經過篩選餘下的7,044條CCCII<>Unicode對應條目以照顧非常用字。例如:
CCCII |
字符 |
Unicode |
| 217570 |
埗 |
U+57D7 |
| 243E2B |
曌 |
U+66CC |
- 由於新表中包含了「多EACC對一Unicode」,而INNOPAC只與其中一條對應,香港科技大學圖書館因此就49組,共109個字符的「多EACC對一Unicode」内碼,展開了「高使用率」研究而設定了優先對應條目。工作小組根據此研究在新對應表中設定了優先對應項。例如:
台 |
EACC |
Unicode |
HKIUG的決定 |
相關繁體字 |
| 27605D |
U+53F0 |
<--27542B較為常用,選為優先對應 |
21605D颱 |
| 283B7D |
223B7D檯 |
| 213538 |
--- |
| 27542B |
21542B臺 |
5.6 EACC/CCCII<>UTF-8 對應表命名為diac.utf8.hkiug,摘要及圖示如下:
EACC<>Unicode:15,673
CCCII<>Unicode:7,044
合共:22,717條目
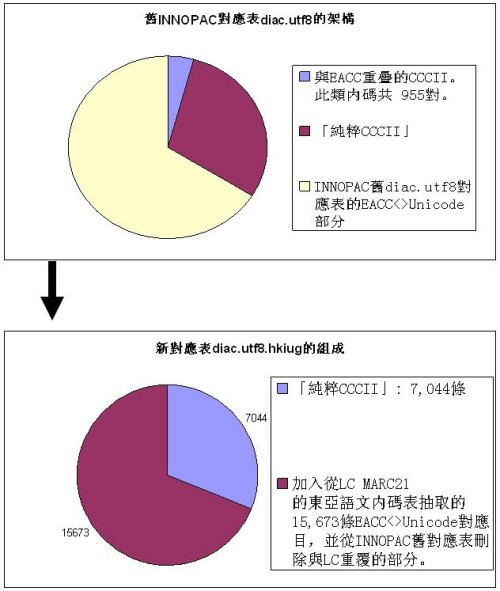
|
6.香港中文大學修改圖書館機讀目錄資料庫過程
6.1 香港中文大學大學圖書館系統在HKIUG確認單一碼計劃工作小組建議的新對應diac.utf8.hkiug之前,已於2003年7月24日開始自行修改内碼。大學圖書館系統爲了避免影響讀者使用目錄,所以在9月大學新學期來臨前先行改碼。
6.2 改碼是使用Millennium INNOPAC的 Global Update 功能,將目錄資料庫中955組 CCCII,轉換成對應的EACC(見前5.5.b)。改碼工作的一個月内,由於圖書館的INNOPAC 系統並不中斷日常運作,而書目紀錄含中日韓字符的目錄多於40万條數據,所以必須分批轉換。先後次序如下:
- 書目檔案中受索引控制部分的内碼 。例如巻(83,842次);家(35,065次);志 (34,353次)
- 書目檔案中不受索引控制部分的内碼
- 權威檔案中受索引控制部分的内碼
- 權威檔案中不受索引控制部分的内碼
6.3 改碼期間,大學圖書館系統Webopac切斷舊Big5 port,只提供UTF8 port給讀者使用。 |
7. 新UTF-8 對應表diac.utf8.hkiug下資料用戶軟件的設定
7.1 對讀者而言,圖書館提供了UTF8 port Webopac;而圖書館則使用Millennium INNOPAC 或其他支援Unicode的Telnet軟件如Anzio-Win為作業平台。
7.2 由於新對應表diac.utf8.hkiug有「多EACC對一Unicode」條目,例如:簡體字 「历」U+5386可對應 27462A 和274349,HKIUG 以27462A為優先對應。若簡體字書目有「万年历」或「万历皇帝」等字樣時,編目者為了準確地把原資料著錄,便需要自行以内碼 {274349} 形式代替字符輸入該字。
7.3 但2003年時Millennium INNOPAC的Millennium Editor Client有缺點,在每筆記錄重存時,會硬按對應表的優先對應的規定把「历」U+5386存為内碼27462A。見附圖:
| CCCII/EACC為内存的資料庫 (多碼) |
|
Unicode為内存的資料庫(一碼) |
27462A(歷 21462A的簡體)
HKIUG定為優先對應 |
历 |
U+5386 |
| 274349(曆 214349的簡體) |
2004年Innovative公司爲了解決這個問題, 提議Millennium Editor Client可使用一個「短對應表」,即是從新UTF-8 對應表diac.utf8.hkiug中剔除「非優先對應」條目。自行輸入的任何内碼由於不存在於「短對應表」中,就得以保存下來。至於讀者的UTF8 port Webopac 仍使用對應表diac.utf8.hkiug。見附圖:
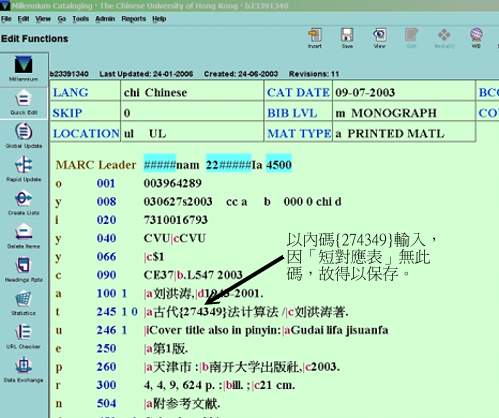
7.4 仍然使用Character-based INNOPAC的圖書館,則需要採用其他支援Unicode的Telnet軟件如Anzio-Win的圖書館,啓動Anzio-Win的CCCII session的同時,並設定獨立的軟件對應表CCCII.UNI。香港中文大學大學圖書館系統自行把diac.utf8.hkiug轉化為Anzio-Win的CCCII.UNI作日常編目之用。
7.5. 既然Millennium Editor Client 能保留編目時自行輸入的内碼,Millennium INNOPAC的MilSer 和MilAcq就可以安心應用了。 |
8. HKIUG的跟進工作
8.1 由於香港的INNOPAC用戶仍會繼續使用CCCII為内存, HKIUG 在2003年單一碼計劃工作小組的基礎上,於2005年接續成立另一工作組,名為「香港Innovative 用戶協會單一碼特別工作組」(HKIUG Unicode Taskforce)負責如下工作:
- 設定TSVCC(Traditional-Simplifed-Variant-Chinese-Characters)混合索引,以解決非優先字不易查找的困難。
CJK 字符中,繁簡體和異體字甚多,不能光靠CCCII特徵的「尾4碼相同」來連結索引。Innovatives 能以 Tool-database 形式達到混合索引的功能,而本特別工作組則提供混合索引條目。當輸入以下任何一個字符,均可把載有以上任何代碼的目錄全部找出來。例如:
213538 台 21542B 臺 27542B 台 21605D 颱
27605D 台 223B7D 檯 283B7D 台3A3B7D 枱
- 繼續維護新UTF8對應表diac.utf8.hkiug,修改Unicode對應,迎合用戶方便,更改對應。例如按照《现代汉语词典》(北京 :商務印書館) 判定那些是異體字。例如:
INNOPAC內碼 |
對應 |
Unicode |
維護決定 |
| EACC 21606A |
原對應 |
U+98EE (飲) |
2003年diac.utf8.hkiug對應表 |
| 新對應 |
U+98F2(飲) |
2005年4月21日HKIUG Unicode Task Force第1次會議 |
- 關注LC MARC21標準内的東亞語文内碼表的更新情況
- 為未來轉移到Unicode為内存的INNOPAC, 做好準備
|
9.未來
9.1 往後數年,圖書館界仍多以 EACC 為記憶體代碼及作為交換碼。以CCCII為内存的INNOPAC 用戶館與此等以 EACC 為記憶體的資料庫進行交換時,不會出現問題。但將來轉用以 Unicode為内存的INNOPAC時,與此等CCCII/EACC資料庫交換時,有些簡體字會輸出cross-walk錯碼。同樣,若圖書館仍採用以CCCII為内存的INNOPAC,接收Unicode的交換目錄,也會受到如上cross-walk錯碼影響。交換資料時cross-walk中的「多碼EACC合為一碼Unicode」不成問題,但「一碼Unicode分爲多碼EACC」則非經人工干預選擇不可。 例如:會有Unicode「万年历」轉換成EACC「万年历 (歷) 」輸出的錯誤。見附圖:
CCCII/EACC為内存的資料庫 (多碼) |
|
Unicode為内存的資料庫(一碼) |
27462A (歷 21462A的簡體) |
历 |
U+5386 |
274349 (曆 214349的簡體) |
9.2 隨著Unicode的普及,INNOPAC已可以由CCCII為内存轉移為以Unicode為内存。大陸的INNOPAC使用館已有或積極考慮轉移到使用以Unicode為内存的INNOPAC。由於Unicode與CCCII碼點形式不同,Unicode的TSVCC必須重訂。 |
10.結語
臺灣地區在中文字碼的研究早已啓動,1999年由國家圖書館出版的《中文字集字碼研究計劃報告》是一份非常詳細精密及有啓發性的報告,為研究中文字集提供的重要文獻。香港中文大學大學圖書館系統在開始探索字碼問題時,亦視此爲主要參考資料。香港的INNOPAC圖書館經過兩年多的討論及研究,已基本解決了字碼的對照,各館已陸續由Big5轉換到Unicode的編目平台。而編目工作也逐步依照原書,以繁體或簡體著錄。在Unicode的平台,可更方便著錄古代文獻中的非常用字。推想Unicode會繼續擴大收集中文字符,增加字庫。將來電腦作業系統亦會能支援更多Unicode的字符,屆時,就算要處理敦煌寫本上的佛經罕見字也不會再有問題了。 |
| |
| 註:黃秉傑及何以業. "The HKIUG Unicode project". (發表於:The 4th Annual Hong Kong Innovative Users Group Meeting, Hong Kong, December 8, 2003).見於http://hkiug.ln.edu.hk/meetings/am2003/presentations/philip_ho_yee_ip.ppt |
(香港中文大學圖書館 編目組(東方語文)主任 何以業)
(香港中文大學圖書館採編及館藏發展組主任 劉麗芝)
|
|








